Making a Blog in Go: a Quest for Simplicity
After years of building thick JavaScript front-ends, I started questioning my ability to write minimal web products. Therefore, I embarked on a journey that led me to the creation of this blog.
This blog ships no JavaScript.
I just wanted to say this, it fills me with an unreasonable amount of joy to be able to say this. For those who might not immediately empathize, I will try to explain myself.
I am part of that generation of developers that started writing web applications in the post-React era. I wrote my first todo apps in React, Vue, and later on, Svelte.
However, I am also a 90s kid, and I remember stealing HTML and CSS from my favorite websites to build my own PHP-powered chat-based RPGs in the early 2000s (more on this one day).
Because of this original, more intimate (pass me the term), experience with the web, I always had mixed feelings about how numbly I was adding kB of dependencies to a web dashboard consumed by few hundred users. Lately, I started strongly revaluating my relationship with the web technologies I have used to develop basically all of my projects since I can recall (React, Express, GraphQL, tRPC, and many others).
This process started with the eye-opening experience of reading Hypermedia Systems, the book by the creators of htmx. They question the indiscriminated proliferation of thick web frontends.
They believe them to be diverging from the very paradigm of the RESTful web based on HTTP, by reducing backends to dumb CRUD middleware facing a database. In order to achieve this, we progressively shifted from an hypermedia-centric approach towards an API-based architecture style that expects front-ends to basically act as desktop applications. While (as also mentioned in the book) I see good reasons to choose the latter approach in many projects, I started questioning whether that was the case for what I had been building in the past.
Then, The Primeagen also put a second bug in my ear when he reacted to WebDevCody. I felt called.
As a side note, I also wanted to learn Go for a while so, after playing around, I started working on a Go+htmx template for my future projects (not all of them, I still like React) and will post about it soon enough. For now though, let's talk about the blog. It is my very first one after all.
What's all the fuss about?
Well, while building this blog I felt like an engineer.
This is because of the following:
- I was in complete control of my output.
- I knew exactly (down to the byte) what was the data flow of my application.
- I was in charge of network requests (and not dependent on a complex client-side router + query engine + hydration mechanism / streaming + you name it).
- I could optimize my Docker image down to the core (this is also thanks to Go being a wonderful minimalistic language) and deploy on GCP (ie. Cloud Run) basically for free.
- I had the mental space to focus on functionality.
This last point seems unrelated, but it's the most important one. I did not feel the appeal of adding unnecessary features by plugging a new dependency in, I carefully selected what felt necessary (e.g. syntax highlighting, as this is going to be mostly a tech blog I cannot compromise on readability), and moved on. I argue this is because, when one steps out of the crowded NPM ecosystem, they might also realize how every import comes at a price.
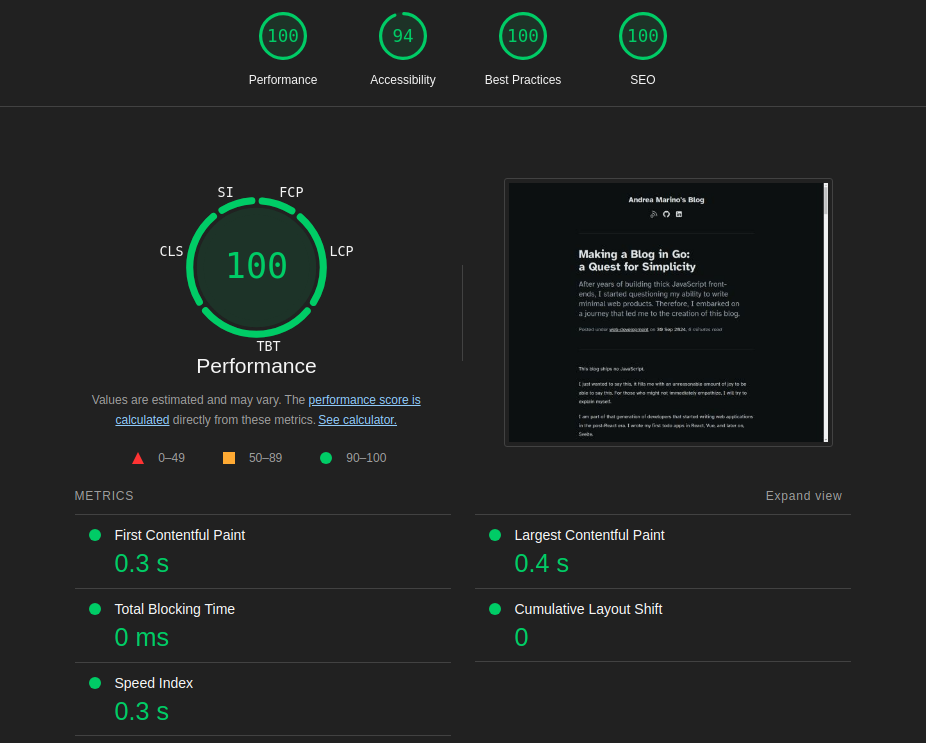
That said, this blog is still refined enough to implement a good typographic system (I might have stolen most of the ideas from tailwindcss-typography, but so what, I am not even using a preprocessor). It also scores great on Lighthouse (see screenshot below, or simply run it yourself). Sure, I am not optimizing image sizes based on viewport like Next.js, but I can see myself implementing it when I have time.
I started asking myself: how production-ready and battle-tested should the implementation of certain things be for me to give up on understanding them and introduce technical debt into my projects?
I would argue it really depends on how core to your business value that specific feature is. Understand, evaluate, choose. This is acting like an engineer, not as a dogmatic follower of the latest JS trend which I have been for too long.
I am not trying to blame client frameworks for all there is wrong in the world of course. I love React-based development. I believe it is one of the best UI development styles I have ever experienced. That said, I just wanted to build a blog. And I ended up doing it with 229 lines of Go (including imports and blanks), 2.3 kB of CSS, and a few html templates. The heaviest thing I am serving to the client is the fonts (I am using 4 variations of Atkinson Hyperlegible adding 16.6 to 18.8 kB each) but at least I am self-hosting, preloading them, and caching them for a year in your browser.
This page is less than 200 kB, as it should be.
How it's made
This post is not meant to be a tutorial. If anything, quite the opposite, take these ideas and make them better. But let's discuss how this is built anyway.
First of all I am using Fiber. It's not really about its performance, more that I really like its public API and plugins capabilities. A few lines to get helmet, compression, and a recovery mechanism. I'll take that. Here's how my router looks like (very Express-y):
1app := fiber.New(fiber.Config{
2 Views: engine,
3 ViewsLayout: "_layout",
4})
5
6app.Use(recover.New())
7app.Use(helmet.New())
8app.Use(healthcheck.New())
9app.Use(logger.New())
10app.Use(compress.New())
11app.Use(favicon.New(favicon.Config{
12 File: "./static/img/favicon.ico",
13}))
14app.Use(limiter.New(limiter.Config{
15 Max: maxConnectionsPerMinute,
16 Expiration: 1 * time.Minute,
17}))
18
19// static is handled differently for each type of file...
20// we can skip over that. I also have route handlers for
21// each page, pretty trivial.
Then, on startup, the main function reads all the markdown files in my /articles folder and stores their YAML front matter metadata in memory using the following struct:
1type Article struct {
2 Slug string
3 Title string
4 CreatedAt time.Time
5 UpdatedAt time.Time
6 Category string
7 Excerpt string
8 WordCount uint32
9}
No database, it is just the filesystem (which is also how I get the UpdatedAt value, just fs.FileInfo.ModTime). With this information I generate both the index page and the RSS feed.
Finally, I am using goldmark to parse actual markdown and render it using Go templates. For example, this article page simply looks like this (wrapped by the root _layout):
1<article>
2 <h1>{{.Article.Title}}</h1>
3 <p class="subtitle">{{.Article.Excerpt}}</p>
4 <p class="metadata">
5 Posted under
6 <a href="/categories/{{.Article.Category}}">{{.Article.Category}}</a> on
7 <time class="created-at" datetime="{{.Article.CreatedAt}}">
8 {{ .Article.CreatedAt.Format "02 Jan 2006" }}
9 </time>
10 </p>
11 <hr />
12 <div>{{.Article.Content}}</div>
13</article>
Oh, I also have this little JSON-LD linked data snippet at the end of every page. I took inspiration from this article for proper HTML semantics and metadata.
1<script type="application/ld+json" id="”BlogPosting”">
2 {
3 "@context": "https://schema.org",
4 "@type": "BlogPosting",
5 "headline": {{.Article.Title}},
6 "url": {{print .RootUrl "/articles/" .Article.Slug}},
7 "datePublished": {{.Article.CreatedAt}},
8 "dateModified": {{.Article.UpdatedAt}}
9 }
10</script>
A note on cloud deployments
Having more mental space to think about my final product, also made me realize that I wanted to optimize for budget. I have quite a bit of experience with GCP, and I still wanted to leverage the amazing DX of building a Docker image with Github Actions and then deploy it on Cloud Run. But Cloud Run can get expensive if you want to avoid cold-starts.
Therefore, I started working on a small Go image (see below). And, thanks to this post by Julia Evans, I also learned about the GOMEMLIMIT and other nice tricks for Go development.
1FROM golang:1.23.1-alpine AS builder
2
3WORKDIR /build
4
5COPY go.mod .
6COPY go.sum .
7
8RUN go mod download
9
10COPY . .
11
12RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -trimpath -ldflags="-w -s" -o main
13
14FROM scratch AS runner
15
16WORKDIR /app
17
18COPY ./articles /app/articles
19COPY ./views /app/views
20COPY ./static /app/static
21
22COPY --from=builder /build/main /app/main
23
24ENTRYPOINT ["/app/main"]
The final image is ~16MB. Not exactly your average Node+Next.js container. However, it will grow over time as I publish more articles and include more images.
Should we also mention that everything here is quite a bit more sustainable? This is a topic for some other post though.
Conclusion
Is this the best blog implementation one could possibly achieve?
Absolutely not.
A blog like this, as it features no interactivity (unlike some incredible websites like Josh Comeau's), can easily be generated fully at build time and served as static files through a CDN. It can feature automated image optimization for different viewport sizes, generation of srcsets at build time, and never even run an application server.
However:
- I understand it from the bottom-up as I built it from scratch (if we do not consider the http server and the markdown parser), and it feels complete in its simplicity.
- I can introduce fancy interactivity in the future with progressive enhancement without compromising the core functionality of delivering text and images.
- It's done, ship it.
I hope this article encouraged someone to look around and rediscover the joy of minimalistic development. I am not talking suckless minimalism, just appreciating the technologies we use every day and are too often hidden behind many layers of dependencies.